
GitHub is to Code as ___ is to DNA
Software to grow biological communities.

Read this post on the Asimov website.
I.
GitHub launched in 2008. Their mission was to build a global platform for developer collaboration. What that means, basically, is they wanted computer programmers to work on projects together by giving them tools to store code (called repositories), track changes to that code, and edit other peoples’ code.
Mission accomplished. The company (now owned by Microsoft) is proof that, if you build useful tools and empower a community, people will come. GitHub is used by more than 100 million developers who have created nearly 400 million repositories.
These repositories contain templates, guides, and code snippets to help any programmer do just about anything. Want to spin up a website? You can find thousands of demos on GitHub. How about a web scraper? There are hundreds of ‘em.
We are inspired by GitHub and believe that biologists should have access to similar tools, but for DNA sequences and experiments instead of computer code. That’s why we’re building a tool, called Kernel, for scientists to store DNA sequences and associated data, share them with others, and track how they change over time.
At a micro-scale, we want to help biologists access the world's growing corpus of biochemical functions and genetic systems, and seamlessly collaborate on projects. At a macroscale, we are trying to accelerate biological progress.
II.
Most genetic engineering projects are ad hoc. If you ask ten genetic engineers to design a biological system to detect lead, you will get ten very different solutions, only some of which are likely to work. Biological progress would move faster if scientists knew what has been tried before, and could track how solutions to problems had evolved over time. This will be especially important as projects grow in sophistication and we try to engineer living cells to do more complex things.
But biologists, and those who seek to engineer cells, are missing basic functionalities that software engineers take for granted. GitHub has three main features that have become a cornerstone of modern programming, and we think similar tools would help scientists, too.
The first feature is repositories, a kind of storage locker for code. Repositories can be copied or shared across the Internet, and marked as public or private. The public ones are searchable, and open-source communities on GitHub are built upon them. Recent research suggests there are more than 28 million public repositories. Developers rarely have to start a project from scratch; they can start with code that someone else has already written.
GitHub repositories also have an Issues tab (but the concept pre-dates the company). This is where people ask questions about code, or request new features. In 2008, though, GitHub introduced pull requests, enabling anyone with access to a repository to write their own changes and then “request” to add them to the project. All of a sudden, a random developer in Kazakhstan could spot a bug in someone else’s repository and write a fix for it, seamlessly. This feature spurred the growth of open-source communities. It shifted collaboration from passive issues into active solutions.
And the final feature is version control. Every time code is altered on GitHub, a digital record is added to the file. The genesis and evolution of every line is meticulously documented, which makes it much easier to find the source of an error or the origin of an idea. Developers can also revert to earlier versions when something goes wrong.
Now, what about biology? Are there any existing parallels?
Not really. There are open-source biology projects, of course, and many benevolent scientists share their notebooks and ideas. But most papers are locked behind paywalls (including nearly half of biomedical papers) and there aren’t really any tools to share, fork, collaborate, or actively make edits on a DNA sequence.
There are many tools to digitally edit DNA, but they lack flexibility in controlling broader access. These tools don’t allow a scientist to, say, open-source a project with all of its DNA sequences and experimental data, giving the entire world the ability to natively and seamlessly fork and modify its contents.
Ideally, it would be as seamless to view DNA sequences, edit them, and share them with others as it is to do all those things with code on GitHub. That’s what better software tools for genetic engineers would enable.
Imagine if any scientist could make a DNA sequence, or fork someone else’s, and store it in a repository. Sequences could be marked as public or private, and shared with any number of individual collaborators who can view, make comments, or edit. This could help grow the open-source community. Every change to a DNA sequence could also be tracked and cataloged over time. The intellectual origins of every sequence would be documented. This would be transformative.
Often, when we modify a DNA sequence in our laboratory, we encounter mundane problems like, “Where did this mutation come from?” or “Why did we add this bit of DNA to the end of this gene?” The answer is rarely obvious. We have spent hours in Slack channels, pinging teammates about where this or that sequence came from. A version control system for genetic engineering would solve this. Every DNA sequence would have a detailed family tree of derivations, highlighting how parts have been combined, modified, or mutated over time.
Finally, our software tool would store all experimental data associated with a DNA sequence — how many copies of an RNA it makes, or how its final protein interacts with others in the cell — in the repository itself. By linking a DNA sequence to outcomes in living cells, it will be easier to design and debug DNA that works in predictable ways in the future.
III.
We’re working on a software tool that will encapsulate all of these features. It’s called Kernel, and we recently launched a beta version to select students.
Kernel has a curated database of 650,000 searchable DNA sequences. Each sequence can be dragged-and-dropped onto a DNA assembly canvas to construct plasmids with custom functions. Kernel also includes a simulator tool that predicts how these DNA constructs will behave inside cells; their transcription rates, protein expression levels, and so on.
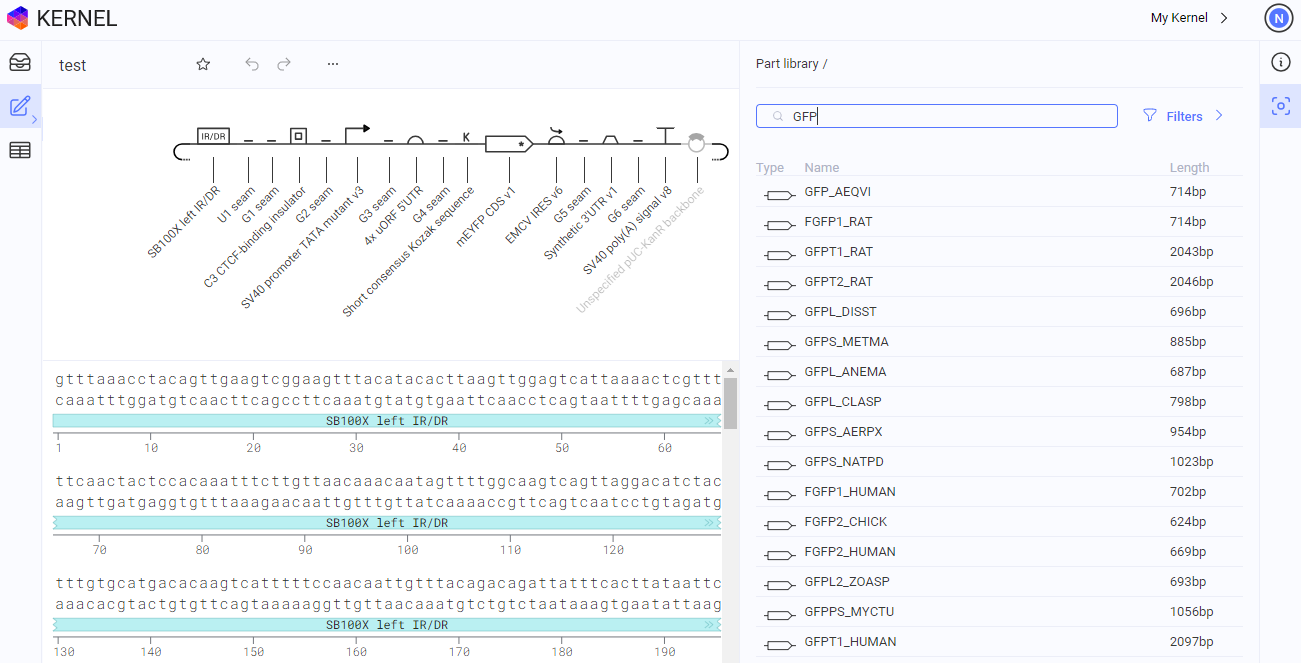
But there’s still a lot of work ahead. We are actively adding version control tools to track how DNA sequences are used or altered over time, for instance, and we are preparing to launch new permissions tools that will make it easier for scientists to collaborate on private projects, or to open-source entire collections of DNA sequences.
Our goal is to build a community around this tool. But we know that’s dependent upon us releasing useful features that make it easier for biologists to do all the things they already do. As the community grows, we hope others will build a suite of custom extensions or plugins to make it easier to design, or debug, biological sequences.
It has not escaped our notice that a GitHub-inspired platform for genetic engineering could enable something analogous to Copilot: an AI-powered tool that generates biological sequences with desired functions. More on that in a future post.
If you’d like to build software tools for genetic engineers, come join us. Or, subscribe for updates.
Contributors: Ben Gordon, Kevin LeShane, Anaïs Moisy, Alec Nielsen & Layton Wedgeworth. Text by Niko McCarty.
Github: Code
Hologenome: DNA